

Note: Will Lansing is the CEO of FICO and Auren Hoffman is the CEO of SafeGraph. This piece is a follow-up to Auren’s 2019 piece: The Data-As-A-Service Bible -- the most widely read piece on the business of selling data.
Data is all the rage these days. Yes, we’ve heard that it is the new oil.
But a single dataset on its own has limited value. The real value from data comes from connecting it across multiple disparate datasets. And to accelerate the connecting of data, it is really helpful if data producers and data consumers agree on a common standard.
In this piece, we will dive into:
- How to make data more valuable
- What makes a good standard
- What standards have worked well in the past
- How new standards in the future can accelerate collaboration around data
If you want to stop reading right now, the tl;dr is:
- Linking data to other data makes all the data more valuable
- Standards (also known as join keys) are the most valuable ways to link data together
- Good standards are platforms that create value for everyone (because everyone uses the standard)
- Successful standards have some common traits both in product design and go-to-market execution
- Perfect is the enemy of the standard -- it is better to focus on something that is good-enough
- Metcalfe's Law also applies to standards: the value of the standard increases exponentially with adoption
- Non-openness and collecting rents impede the success of a standard, because it impedes adoption
- Standards should be SIMPLE

The easiest way to increase data’s value is by linking it together.
Metcalfe’s Law shows that the value of a network grows in proportion to the square of the number of nodes in the network. We all understand that intuitively: a telephone is not very valuable if you can only call yourself. The reason messaging systems like WhatsApp are super useful is that a lot of other people also use WhatsApp.
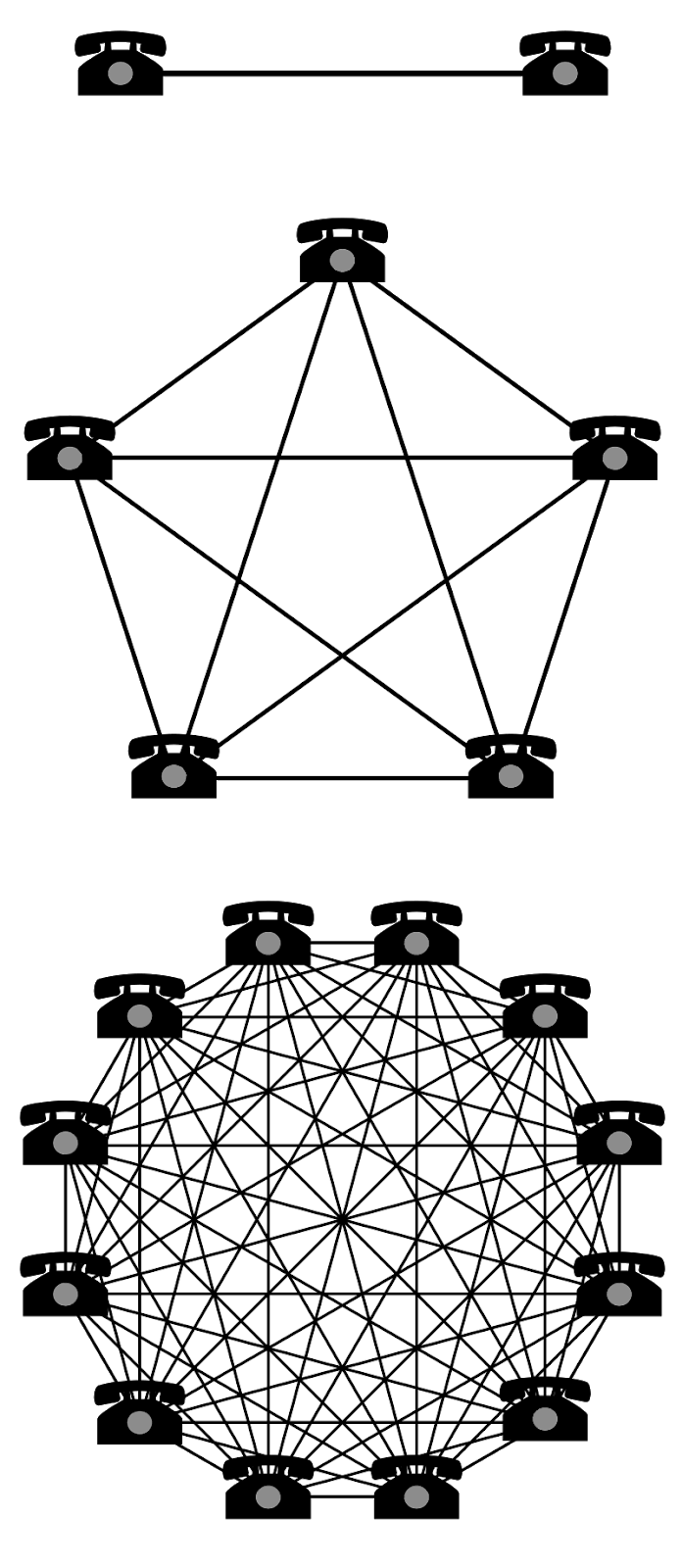
What most people don’t realize is that Metcalfe’s Law applies to data too. The more connected a dataset is to other data elements, the more valuable it is. And the easier it is to link your data, the more valuable it becomes. From the DaaS Bible:
The reason for this is simple: data is only as useful as the questions it can help answer. Joining, linking, and graphing datasets together allows one to ask more and different kinds of questions.
No one company or organization has a monopoly on data. Even mighty Amazon only knows less than 0.1% of what is happening in the economy. Even the Internal Revenue Service and the Federal Reserve have limited insights into the world. And even Google, which has access to more data about people than any other company in the world, still has mostly incomplete information.
So, to truly understand something, you need to bring together data from as many different sources as you can. The days of doing a psychology study on 18 undergrads and attempting to generalize to the broader world are long-gone. Large data sets are out there, and to make them valuable, you need to link them together with join keys.
Join keys are the secret to connecting datasets.
Join keys are really valuable. They are just simple connectors that make it super easy to take many different datasets and bring them together.
If you are an investor and you are trying to value a dataset, the easiest thing you can do is first recognize how many join keys there are in this dataset that can allow end-users to bring in additional data.
By definition, join keys are derived. They’re also fairly simple, and as a consequence, also imperfect. Join keys get their power not from solving every problem or working on every use case, but from the fact that they are used by many other organizations. Remember Metcalfe's Law? The more organizations that use the join key, the more valuable it is.
Data is most powerful when it’s standardized.
Case study: Unix time as a standard.
One great join key is time. Unix time (or other standards like UTC) standardize time zones so that an event that takes place at the same exact time in Lagos, Moscow and Sydney are represented as such.
Unix time is a standard convention around time, but it’s not perfect. Unix time might say it is Tuesday when it is actually Monday in San Francisco -- so things can be confusing.
Unix time is represented by a simple integer that is the number of seconds since January 1, 1970. Forgive us, but weren’t there significant events before 1970? (one of the co-authors of this piece was actually born before 1970 … we will let you guess which one). Do we really want a standard that represents everything before 1970 in hard-to-use negative numbers? The answer is yes -- because the perfect is the enemy of the standard.
Unix time’s main power is that it is accepted as the convention to measure time. This means applications and computers all over the world can easily share and receive information about time. And Unix time is only a small improvement over the previous standards (like Greenwich Mean Time or GMT).
One of the nice things about Unix time is that it can be represented as a string of numbers -- which means it can very easily be stored in a database and running calculations on it is simple math of adding or subtracting seconds.
To reiterate, the power of Unix time is that everyone else uses it. Yes, it is clever. Yes, it is simple. But its widespread adoption as the standard is what makes it useful.
Case study: the Meter and measuring distance
A long time ago, one measured how big their farm was by taking steps. This was obviously an imperfect way of representing the size of one’s lot or the distance between two cities … but it was accepted and it (mostly) worked.
Today we have the meter as a standard.
Developed in post-revolutionary France in the 1790s, the meter has conquered the world (at least everywhere except the United States) as the standard for measurement.
Like all standards, the meter isn’t perfect. Why should the meter be the length it is? Would it be more practical for a “meter” to be larger or smaller? Yes, of course. But remember, the perfect is the enemy of the standard.
The meter is clever. It can be easily subdivided (centimeters, etc) and expanded (kilometers, etc.) which is why the metric system has taken over science from the English system (we still can never remember how many feet are in a mile).

But the cleverness of the meter is only a small part of its success. Its main reason for success is that everyone else has adopted it. If you are a business selling and buying materials across the world, it is really helpful that everyone uses the same system for measuring length. The more organizations who use the same standard, the more useful that standard becomes. Again, it’s Metcalfe’s Law in action.
The meter is successful because enough people think it will be successful. All great standards are recursive. (of course, it can’t hurt to have the reigning emperor of Europe, Monsieur Bonaparte, as your cheerleader)
To standardize a data set, it helps to be Free, Open, and Usable.
One of the advantages of Unix time and the meter is that the standards are free and open. In fact, it is MUCH easier for something to become a standard if it is free and open because the barrier to adoption is low.
It is doubtful the meter would have taken over the world if Napoleon decided to charge a small tax every time the meter was used.

It is also easier for a standard to be adopted if it is locally storable under a simple license.
Some data might seem open but there can be a hidden tax that can impede wide adoption. Data licenses like ODbL (Open Data Commons Open Database License) force people using the data to contribute back to the community. While that is great in many cases, many commercial entities will be wary of mixing in ODbL data with their proprietary data. Imagine if the meter was only offered in an ODbL license -- every time your doctor wanted to record your height, she’d have to also send it to a central “meter foundation.”
A better open-source license for standards is the MIT license which allows commercial and non-commercial entities to use, store, and develop on the project without contributing back to the initiative. Of course, contributions are very much appreciated … but making contributions mandatory impedes the success of a standard. Again, the perfect is the enemy of the standard.
Case study: FICO® Score as standardized data.
The FICO® Score has become a standard to measure the overall likelihood that someone will repay a loan. The FICO Score is used by over 90% of top US lenders when making lending decisions.
Typically, the higher your score, the lower the risk and the more likely creditors are to lend to you.
The nice thing about the FICO Score is that it is simple and storable. It is a three-digit number and it is easy for both a human and a computer to understand. Someone with a 550 score is higher risk to lenders than a person with 760.
Of course, the FICO Score is far from perfect. Two people with the exact same score may end up having differences in loan repayment.
Another way the FICO Score isn’t perfect is that it is not free. Lenders need to pay to get the FICO Score. Charging for a standard can often impede the chance that the measurement becomes a standard (because to be a standard it must be widely adopted). The flip side of charging for the standard is that one can use that revenue to continually update it and make it better.
Unix time has gotten a wee bit better over the last 40 years (a few leap seconds have been added here and there). In contrast, the FICO Score has hundreds of people working on improving it every year.
So like all standards, the FICO Score isn’t perfect. But remember, perfect is the enemy of the standard. The FICO Score is a very good predictor of a person’s ability to repay a loan. The fact that almost every consumer, bank and credit institution understands and uses the FICO Score makes it much easier for the economy to function, because every party on all sides of every contract are speaking the same language. Re-enter Metcalfe’s Law.
Standards unlock massive value for the networks that use them.
Standards are really important because they create a common language to foster communication. If everyone spoke a different language, we’d never get anything done. Standards are both the glue that connects datasets together and and the grease that make data flow between organizations.
One of the advantages of Unix time is that it is both a standard and also a useful join key. Let’s say we want to join the stock price of Tencent and Microsoft and see how correlated the two stocks are immediately after news breaks. Unix time allows us to join the stock data together based on time even though they are traded in two different jurisdictions, adding huge value to both jurisdictions.
Another standardized join key that is super useful is the U.S. dollar. While different exchanges around the world are often listed in their national currency, they can be easily compared by converting them to the U.S. dollar. Yes, one could use a different currency (or even the price of gold or bitcoin at the time), but a standard is just a convention that we all agree to use. The dollar is not necessarily a better measure than another currency or store of value, but it is the agreed-upon standard that we all use. As we have stated before: the perfect is always the enemy of the standard.

Language itself can standardize as well. The World Economic Forum brings together leaders from all over the world every January in Davos. These leaders all speak different languages, but the Davos gatherings are in English. And no, that’s not perfect -- not everyone who attends speaks or understands English … but it is an agreed-upon standard because it is good enough and unlocks value for most attendees.
Standards unlock value in data in three key ways:
- Enables understanding -- use of standards promote common and clear meanings for data
- Democratizes access and availability -- standards make the exchange, interpretation and integration of data easier and more efficient
- Increases use --> which drives access --> which in turn drives more use/reuse of data; more the data is used, the more valuable it becomes
Standards accelerate collaboration around data
The easier it is to join data, the more data will be transacted, moved, and used.
Because it is so easy to join data on price (the dollar is a common-enough measure), it becomes easier and easier to join data about prices.
But let’s say there is a world where people get paid in Bitcoin but they buy homes with platinum … you’d want to make sure these measures of value were joined before you did your analysis about how correlated home prices were to income. The join key (right now we use dollars) becomes really important for any type of correlation or relationship across datasets.
As we said earlier:
The more connected a dataset is to other data elements, the more valuable it is. And the easier it is to link your data, the more valuable it becomes. The reason for this is simple: data is only as useful as the questions it can help answer. Joining, linking, and graphing datasets together allows one to ask more and different kinds of questions.
Even the simplest questions may have very complicated operations to answer. For example, let’s say we wanted to understand the global price consumers spent on milk over time. We will have to use multiple join keys just for this one elementary analysis. First we’d need to join on a measure of price (like the dollar). Then we have to choose what version of the dollar we are joining on (like the inflation adjusted dollar on Jan 1, 2010). Then we have to understand the rate of inflation we use and if we want to change it in each country. Then we have to understand the measure of milk that we are using (like the U.S. uses gallons but much of the rest of the world uses liters). Then we need to understand what kind of milk we are talking about (like in many countries, milk is not pasteurized and might not last as long). And we will need to have an understanding of what type of consumer we are looking at (we might want to discount the Brooklyn hipster that only buys the artisanal fully organic milk where the farmer reads daily bedtime stories to the cows).

The easier it is to join the data, the more the data will be joined … and the more the data will eventually be used. One of the biggest reasons that most academic papers are written with only 1 or 2 datasets isn’t because of the difficulty in acquiring data (though that is certainly one of the issues), it is that it is so incredibly difficult to join disparate slices of data.
What makes a great standard?
The very best standards act as join keys that unlock data in multiple datasets.
From the DaaS Bible:
If the value of Dataset A is X and the value of Dataset B is Y, the value of joining the two datasets is a lot more than X+Y. Because the market for data is still very small, the value isn’t X*Y yet … but it is possible it will approach that in the future.
Data becomes much more valuable the more additional datasets it can be joined to. And no, data owners don’t need to make money off of those other datasets -- those other datasets make your data better. As stated in the DaaS Bible:
This is the #1 thing that most people who work at data companies do not understand. Most people think that they need to hoard the data. But the data increases in value if it can be combined with other interesting datasets. So you should do everything you can to help your customers combine your data with other data. One way to make data easy to combine is to purposely think about linking it — essentially creating a foreign key for other datasets.
Joining your data to other datasets is what makes your data more valuable … and it makes sense to spend a lot of time investing in join keys.
The best join key standards are SIMPLE.
The SIMPLE acronym for data companies helps guide the creation of a universal identifier that is:
- Storable. You should be able to store the ID offline. For instance, I know my SSN and my payroll system stores my SSN.
- Immutable. It should not change over time. An SSN on a person is usually the same from birth until death (except if you enter the witness protection program).
- Meticulous (high precision). The same entity in two different systems should resolve to the same ID. It should be very difficult for someone to claim they have a different SSN.
- Portable. I can easily move my SSN from one payroll system to another.
- Low-cost. The ID needs to be cheap (or even free). If it is too expensive, the transaction costs will make it hard to use in many situations. The SSN itself has no cost.
- Established (high recall). It needs to cover almost all of its subjects. An SSN covers basically every American taxpayer (and more).
One example: the Placekey is a join key that has a common identifier for all physical places. Prior to the Placekey, it took a very sophisticated engineering team to join data on a postal address. The Placekey is a simple string that can easily be joined. It is SIMPLE, free, and open. All companies that sell geospatial data, like SafeGraph, benefit when the data is easier to consume. All companies that consume geospatial data (like Esri, Carto, Mapbox, Unfolded, Apple, Twitter, Microsoft, etc.) benefit when data is easier to access.
Some ideas on creating a standard in your industry.
If a standard does not already exist in your industry, it might be a good idea to help create one. Here are some ideas around building a standard:
Your standard should lift all boats.
The definition of a standard is that it lifts all boats. Remember how the U.S. dollar added value to all the other national currencies by creating a standardized comparison tool for all of them? That’s the goal of any standard you create. It should help everyone in the community.
Even companies can be standards: if they put their customers first
Insurance Services Office (ISO) (which is now a division of Verisk) was started in the 1970s to help insurance companies better underwrite and combat fraud. It was a data co-op that benefitted all insurance companies and very quickly made the entire industry more streamlined and profitable. While ISO is for-profit and charged for its services, it lifted all the boats in the insurance industry by creating a common standard.
Visa is another example of this. After Visa was created (spun out of Bank of America in 1970), it operated as a not-for-profit organization for many decades. Dee Hock, Visa’s trailblazing CEO, passionately promoted Visa’s neutral status that allowed it to become a payments standard and help its thousands of partner banks. Today the Visa standard of payment rails powers trillions of dollars in transactions … and that would never have happened if it did not put its customers first.
Open-source first companies are also an example of creating the product as a standard. Red Hat was one of the true pioneers in creating a for-profit company around an open-sourced standard (in this case, LINUX). Other notable companies include Databricks, Cloudera, Confluent, and many others.
Your standard should be low-cost.
One of the best ways to FAIL at creating a standard is to try to take too many rents or make it proprietary. Yes, there are amazing examples of proprietary standards, but they are generally the exceptions. A standard is a public good (which is why so many of the most well known standards have been created by or mandated by governments).
Your standard needs the support of industry competitors, regulatory bodies, etc.
Let’s say you run a company FoodDataGraph that has data on what people eat. Collecting this data and joining this data is an incredible problem. How do you categorize each thing someone eats? Is a hamburger its own entity or does it get split into meat, bun, lettuce, and tomato? How does that get joined to other datasets (like if you want to figure out calories, nutritional information, food source data, food vendor data, prices, etc.). How do you know a menu item from one restaurant is roughly the same as a menu item in another?
It is not clear. But one thing is for sure, if you want to create a standard you cannot do it yourself. You are going to need a lot of other companies to adopt it.
Huge food delivery companies (like Sysco and U.S. Foods -- and also Doordash, Grubhub, and UberEats) might be a good start. Big groceries (WalMart, Safeway, etc.), restaurant chains (like McDonald’s), and restaurant associations would also be good to get buy-in from. And eventually you might want to rope in the FDA to help bring the standard over the line.
Adoption will be much faster if everyone (including your direct competitors) have open access to the standard. Remember, a great standard lifts all boats -- not just yours.
When standards disappear, entire ecosystems can die.
Once standards get going, it is important that they last. Often billions of dollars are relying on the standard. If they do go away, it is important there is a reasonable replacement. Like if meters were abolished in science, we could use the English measurement system. It’s not ideal, but it will work. One could switch from the US Dollar to the Euro or just back to gold. It is not ideal but the switch can happen.
We often want a standard for an industry (like Verisk in insurance) but we are afraid to bet on one because there is no assurance that the standard will be around for decades. The good news is that standards, once in place, often last a lot longer than anyone would have expected. Even when the standard itself is suboptimal, like the QWERTY keyboard, standards often persist well after their initial perceived expiration date.
There is power in a standard. But as Voltaire (sometimes attributed to Spiderman’s Uncle) said: “with great power comes great responsibility.”
Adding standards is hard … and humbling
The first thing you’ll find when working to start a standard is that there are 20 other projects that have started to solve the same problem -- some of those will be alive and some will be long dead.
It is humbling to start a standard because the chance of success is low. The more the standard is SIMPLE, the higher chance it has of success. But that does not mean it will be easy to achieve ubiquity.

Your standard should be built to exist forever
The great paradox of standards-building is that organizations and individuals who may benefit from that standard will be nervous to adopt a new standard without knowing others are already using it. Utilizing and operationalizing a standard within organizations takes time - whether it’s the engineering team that needs to change their data pipelines or the sales team that needs to communicate how their data product can more easily integrate with this new standard.
Creating a standard is really hard. The chicken-egg problem exists tenfold when one is developing a standard. One thing to help kick-start any standard is to show it will be around for a very long time.
Your standard should be thought of and built so that it will last forever. There are various ways to support something forever, whether it be through open source software, easily computable, supported by a coalition of members, supported by a government entity (although this can also be impermanent), supported by a foundation, etc. It is up to you to figure out the best way to ensure your standard can last forever - but there are many different ways you can solve for the “forever problem.”
Your standard may need to continually adapt
Some standards are like the meter -- you set it and forget it.
Some standards need to change and evolve over time -- like the FICO Score -- or like an OS like LINUX.
The more your standard is in the “set it and forget it” camp -- the more you need to get it correct. Or at least need to keep building on top of it over time (the QWERTY keyboard has become an imperfect standard that we will likely keep for a very long time).
The more your standard needs to evolve, the more it looks like a company or ongoing project. In these cases, you don’t need to get everything right up-front but you will need to adapt and change quickly. These standards need to continually improve or they will die
Think of your standard as a platform.
Bill Gates’ famous definition: “a platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it. Then it's a platform” also applies to standards. Standards are a platform. A standard join key is the ultimate (and original) platform.
A standard is the OG of platforms.
Make your standard SIMPLE.
If you want to create a standard, try to keep it as SIMPLE as possible. The closer it is to SIMPLE, the more likely it will both be adopted and be enduring. Remember, SIMPLE means:
- Storable.
- Immutable.
- Meticulous.
- Portable.
- Low-cost.
- Established.

And heed our advice, don’t try to make the standard perfect. Don’t try to please everyone. That will never, ever happen. All standards are incredibly flawed. The most important thing about a standard is that it is good enough to get adopted, not that it is perfect.
The perfect is the enemy of the standard.
Thank you for reading this. We’d love your comments, ideas, and critiques. We also would love to hear about standards in your industry and what you learned from them.
Special thanks to the following people for their help and edits: Lauren Spiegel, Ryan Fox Squire, Ross Epstein, Thomas Waschenfelder, Ravi Patel, Evan Barry, and many others.
Note: SafeGraph is hiring. If you want to work at a data company, consider applying for SafeGraph careers.


.png)

.png)
.png)
